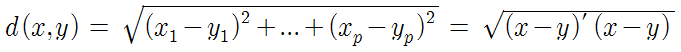1. 군집분석 (1) 개념 -각 객체의 유사성을 측정하여 유사성이 높은 대상 집단 분류 -데이터들 사이의 거리를 기준으로 군집화 - 요인분석은 유사한 변수(열단위에 해당)를 함께 묶는 것이 목적이라면, 군집분석은 행(레코드) 값을 묶는 것 - 판별분석은 사전에 집단이 나누어져 있는 자료를 통해 새로운 데이터를 기존 집단에 할당하는 것이 목적 2. 거리 측정 (1) 연속형 변수인 경우 ① 유클리디안 거리 - 데이터 간 유사성 측정 시 사용하는 거리 - 통계적 개념이 내포되어 있지 않아, 변수들의 산포 정도가 감안되지 않음 ② 표준화 거리 : 표준편차로 척도 변환 후 유클리드안 거리를 계산하는 방법 ③ 마할라노비스 거리 : 통계적 개념이 포함된 거리며, 변수들의 산포를 고려하여 표준화한 거리 ④ 체비셰프 거..